Quick Disclaimer: I don’t work for Dropbox and don’t know anybody that does. I have no inside knowledge, but just based on my following them and putting things together, this is my interpretation of how they are printing money.
This might get a bit complicated, but follow me for a second.
TL DR Version
Dropbox stores only 1 copy of every unique file and serves everybody the same unique file - provided that it is the exact file - but charges everybody for the full file size. E.g. if 1 person uploads a 5MB file, but 99 other people upload it too, they don’t have 100 copies of that 5MB file for 500MB of storage. The only use 5MB of storage, but charge everybody’s quota of 500MB.
Long Version
At first glance, when you think about Dropbox’s cost structure, it seems sub-phenomenal. It seems ok. Just like any other ‘infrastructure as a service’ where their Gross Profit Margins (i.e. Gross Profits after Cost of Goods Sold is paid from Revenues) are about 70% - 85% depending on who you believe.
But I am going to demonstrate that it could be higher than we have ever seen for any other type of service.
So let’s get to a little math, and a few assumptions.
Let’s say that everybody on Dropbox that has a paid account is maximizing the space they are alloted. The reason we are assuming this is so that we can see how the model looks in the ‘worst case’ scenario - which is no doubt what any conservative/responsible entrepreneur should be looking at. If someone is paying for storage they are not using, that’s pure profit - so that will add to the attractiveness of the model.
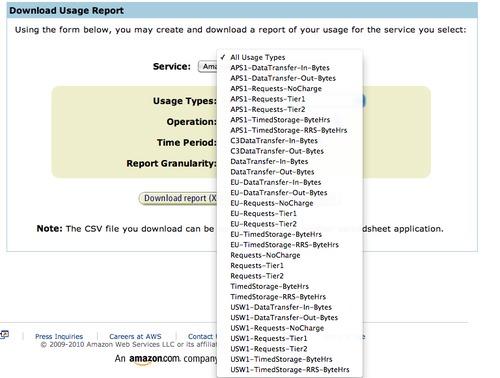
Let us say that Dropbox is paying $0.15/GB (which I know they are not because they are using A LOT of storage, but I will address that later).
So paid users pay $10/mo for 50GB storage. That means, Dropbox’s cost for that account is 50GB X $0.15/GB = $7.50.
At first blush, that seems HORRIBLE. Dropbox’s Cost of Goods Sold (COGS) is 75% of their revenues?
Walmart - a retail company that you expect to have a very high cost of revenue based on their low cost model - has COGS of 75% (according to the latest fiscal year, their revenues were $405B with COGS of $304B, so 304/405 = ~75% . So you mean to tell me that Dropbox has the same business model as Walmart? Yuck!!
However, let’s factor in the fact that Dropbox gets the best publicly available rate from Amazon for storage at $0.055/GB. What does their COGS look like now?
50GB X $0.055/GB = $2.75. Ok, that’s a bit better. But that is still COGS of 27.5%. Seems a bit high for ‘SaaS’ services.
Salesforce has COGS of 19.75% of Revenue for their last fiscal year - $257.93M/$1,305.58M = 19.75%.
So even for a SaaS business that looks high.
Dropbox has 6M users, approximately, and supposedly
uses a TON of storage. So their monthly Amazon bill must be ginormous….or is it?
Dropbox is kind of like taking the best elements of subversion, trac and rsync and making them “just work” for the average individual or team. Hackers have access to these tools, but normal people don’t.
In computing, diff is a file comparison utility that outputs the differences between two files. It is typically used to show the changes between one version of a file and a former version of the same file.
When I asked Ferdowsi which feature on Dropbox he likes that is underused he told me about the Undelete feature:
“Anytime a file is deleted on your Dropbox or a file is changed, Dropbox records a snap shot and stores it. So you can go back to any point. If you’re a free user you can go back 30 days. If you’re a paid user you can go back to unlimited revisions. So it’s cool to know you can go back to a file you deleted 2 years ago”.
Think about that for a second, on top of having higher than normal COGS for a SaaS app - they also offer a substantial free service (2GB + 250MB per referral up to 4/5GB) and they offer ‘undelete’ where the files of free users are stored for 30 days and paid users forever. This one little feature is mindblowing. Because what that essentially means is that everybody can have unlimited storage for just $10/mo. How do you ask? Well, say you have 50GB of stuff uploaded in month 1. You delete 45GB and upload a new 45GB. If you ever want anything from the first 45GB, all you have to do is delete enough space in your current 50GB and restore that portion. So say you want 5GB that were delete from month 1, all you do is delete 5GB in month 2 and restore that set from month 1, then you can delete the newly restored data and restore month 2 data when you are done. If you do this perpetually, obviously it will be annoying - but in theory, someone could have unlimited storage forever for only $10/mo.
So that puts a spin on this model. Given that people decided to do that, if Dropbox paid for every GB it sold, it would be bankrupt VERY quickly. Because they are storing 100GB for a user that is only paying for 50GB.
So this is where the printing money comes in.
What they do, I think because it has not been told to me and I know no one that works there, is they store only 1 copy of a file that is uploaded that has never been uploaded before (i.e. they check makeup of the file, using something like the diff utility that I defined earlier) and then serve that 1 file to everybody that requests that file. Don’t believe me? Download a popular file that many people would likely download - e.g.
Open Office for Windows (note that download will start) - and put it in your dropbox folder. See how long it takes to upload. Mine just took less than 1 minute, and that’s a 241MB file. Could it be that your internet speed is so fast that it uploads the entire file in a minute or two - or is there something else happening behind the scenes?
I suspect the latter.
So my theory is this, they take the first unique copy of every file (i.e. the identical file) and store that one. They then simply have a pointer to that file in everybody else’s folder. So whenever anybody wants to share it, they send them the pointer to that 1 file and don’t create a copy. So in theory, when 1 person uploads a 5MB file, and 99 other people upload that same file - they simply create pointers (or an index) for those 100 people and have the 1 file stored. So they store only 5MB + whatever small size the pointers/index come up to, but they ‘charge’ the quota of those 100 people for a total of 500MB. Essentially they charge for 500MB but only use 5MB.
Network effects apply here, in that the more people upload to the system, is the lower their costs become over time. Because they keep charging additional people for access to the same content. So there could conceivably be the cases where people are paying for 50GB storage, and Dropbox is paying nothing for that particular 50GB because they are using files that are already on the server. It’s hard to calculate the COGS in this scenario because there are so many variables - but I have no doubt that it is lower than regular SaaS (because the average SaaS service pays for every GB their user uses).
That’s the theory in a nutshell. Needless to say, as Dropbox grows their profits will just grow because there will be more files indexed and more people paying for those single files. They just have to pay for the transfer - which is minimal since most people are not accessing most files many times per month - and they can get the best rates because of growing economies of scale.
I hope no one misinterprets this as an attack on Dropbox, but rather a post of adulation. I love it. This business model is truly gold.
I don’t think it is hyperbole to say that I haven’t encountered any other business model that produces as much profit as this one. It combines the best elements of
fractional reserve banking, SaaS cost structures and low-cost viral marketing.
If this is what they are doing, Drew Houston, Arash and the rest of the Dropbox team should be bought drinks. Because they just figured out how to print money legally.
If they are not doing this, they should buy me a drink for showing them how to print money legally :)